Refreshable Materialized View
Refreshable materialized views are conceptually similar to materialized views in traditional OLTP databases, storing the result of a specified query for quick retrieval and reducing the need to repeatedly execute resource-intensive queries. Unlike ClickHouse’s incremental materialized views, this requires the periodic execution of the query over the full dataset - the results of which are stored in a target table for querying. This result set should, in theory, be smaller than the original dataset, allowing the subsequent query to execute faster.
The diagram explains how Refreshable Materialized Views work:
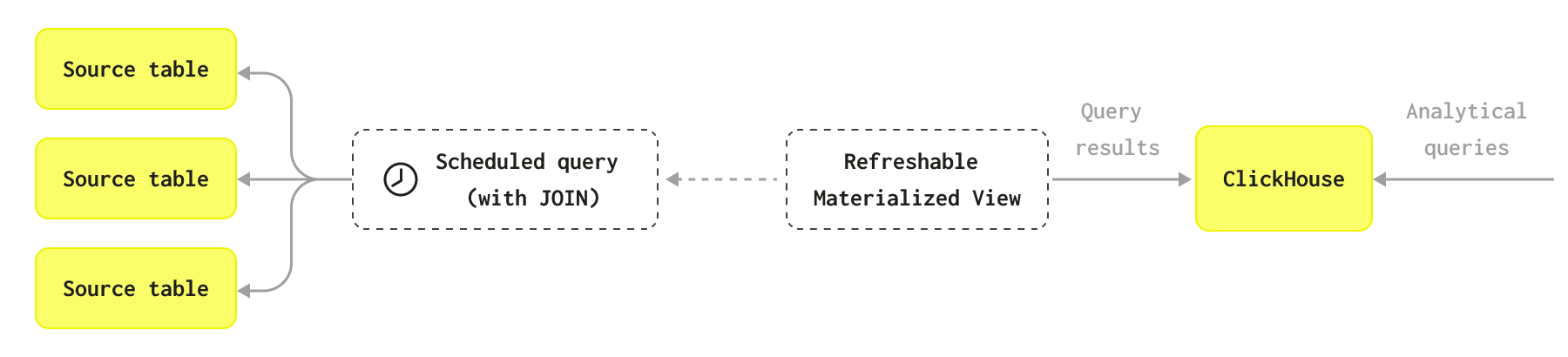
You can also see the following video:
When should refreshable materialized views be used?
ClickHouse incremental materialized views are enormously powerful and typically scale much better than the approach used by refreshable materalized views, especially in cases where an aggregate over a single table needs to be performed. By only computing the aggregation over each block of data as it is inserted and merging the incremental states in the final table, the query only ever executes on a subset of the data. This method scales to potentially petabytes of data and is usually the preferred method.
However, there are use cases where this incremental process is not required or is not applicable. Some problems are either incompatible with an incremental approach or don't require real-time updates, with a periodic rebuild being more appropriate. For example, you may want to regularly perform a complete recomputation of a view over the full dataset because it uses a complex join, which is incompatible with an incremental approach.
Refreshable materialized views can run batch processes performing tasks such as denormalization. Dependencies can be created between refreshable materialized views such that one view depends on the results of another and only executes once it is complete. This can replace scheduled workflows or simple DAGs such as a dbt job. To find out more about how to set dependencies between refreshable materialized views go to CREATE VIEW,
Dependenciessection.
How do you refresh a refreshable materialized view?
Refreshable materialized views are refreshed automatically on an interval that's defined during creation. For example, the following materialized view is refreshed every minute:
CREATE MATERIALIZED VIEW table_name_mv
REFRESH EVERY 1 MINUTE TO table_name AS
...
If you want to force refresh a materialized view, you can use the SYSTEM REFRESH VIEW clause:
SYSTEM REFRESH VIEW table_name_mv;
You can also cancel, stop, or start a view. For more details, see the managing refreshable materialized views documentation.
When was a refreshable materialized view last refreshed?
To find out when a refreshable materialized view was last refreshed, you can query the system.view_refreshes system table, as shown below:
SELECT database, view, status,
last_success_time, last_refresh_time, next_refresh_time,
read_rows, written_rows
FROM system.view_refreshes;
┌─database─┬─view─────────────┬─status────┬───last_success_time─┬───last_refresh_time─┬───next_refresh_time─┬─read_rows─┬─written_rows─┐
│ database │ table_name_mv │ Scheduled │ 2024-11-11 12:10:00 │ 2024-11-11 12:10:00 │ 2024-11-11 12:11:00 │ 5491132 │ 817718 │
└──────────┴──────────────────┴───────────┴─────────────────────┴─────────────────────┴─────────────────────┴───────────┴──────────────┘
How can I change the refresh rate?
To change the refresh rate of a refreshable materialized view, use the ALTER TABLE...MODIFY REFRESH syntax.
ALTER TABLE table_name_mv
MODIFY REFRESH EVERY 30 SECONDS;
Once you've done that, you can use When was a refreshable materialized view last refreshed? query to check that the rate has been updated:
┌─database─┬─view─────────────┬─status────┬───last_success_time─┬───last_refresh_time─┬───next_refresh_time─┬─read_rows─┬─written_rows─┐
│ database │ table_name_mv │ Scheduled │ 2024-11-11 12:22:30 │ 2024-11-11 12:22:30 │ 2024-11-11 12:23:00 │ 5491132 │ 817718 │
└──────────┴──────────────────┴───────────┴─────────────────────┴─────────────────────┴─────────────────────┴───────────┴──────────────┘
Using APPEND to add new rows
The APPEND functionality allows you to add new rows to the end of the table instead of replacing the whole view.
One use of this feature is to capture snapshots of values at a point in time. For example, let’s imagine that we have an events table populated by a stream of messages from Kafka, Redpanda, or another streaming data platform.
SELECT *
FROM events
LIMIT 10
Query id: 7662bc39-aaf9-42bd-b6c7-bc94f2881036
┌──────────────────ts─┬─uuid─┬─count─┐
│ 2008-08-06 17:07:19 │ 0eb │ 547 │
│ 2008-08-06 17:07:19 │ 60b │ 148 │
│ 2008-08-06 17:07:19 │ 106 │ 750 │
│ 2008-08-06 17:07:19 │ 398 │ 875 │
│ 2008-08-06 17:07:19 │ ca0 │ 318 │
│ 2008-08-06 17:07:19 │ 6ba │ 105 │
│ 2008-08-06 17:07:19 │ df9 │ 422 │
│ 2008-08-06 17:07:19 │ a71 │ 991 │
│ 2008-08-06 17:07:19 │ 3a2 │ 495 │
│ 2008-08-06 17:07:19 │ 598 │ 238 │
└─────────────────────┴──────┴───────┘
This dataset has 4096 values in the uuid column. We can write the following query to find the ones with the highest total count:
SELECT
uuid,
sum(count) AS count
FROM events
GROUP BY ALL
ORDER BY count DESC
LIMIT 10
┌─uuid─┬───count─┐
│ c6f │ 5676468 │
│ 951 │ 5669731 │
│ 6a6 │ 5664552 │
│ b06 │ 5662036 │
│ 0ca │ 5658580 │
│ 2cd │ 5657182 │
│ 32a │ 5656475 │
│ ffe │ 5653952 │
│ f33 │ 5653783 │
│ c5b │ 5649936 │
└──────┴─────────┘
Let’s say we want to capture the count for each uuid every 10 seconds and store it in a new table called events_snapshot. The schema of events_snapshot would look like this:
CREATE TABLE events_snapshot (
ts DateTime32,
uuid String,
count UInt64
)
ENGINE = MergeTree
ORDER BY uuid;
We could then create a refreshable materialized view to populate this table:
SET allow_experimental_refreshable_materialized_view=1;
CREATE MATERIALIZED VIEW events_snapshot_mv
REFRESH EVERY 10 SECOND APPEND TO events_snapshot
AS SELECT
now() AS ts,
uuid,
sum(count) AS count
FROM events
GROUP BY ALL;
We can then query events_snapshot to get the count over time for a specific uuid:
SELECT *
FROM events_snapshot
WHERE uuid = 'fff'
ORDER BY ts ASC
FORMAT PrettyCompactMonoBlock
┌──────────────────ts─┬─uuid─┬───count─┐
│ 2024-10-01 16:12:56 │ fff │ 5424711 │
│ 2024-10-01 16:13:00 │ fff │ 5424711 │
│ 2024-10-01 16:13:10 │ fff │ 5424711 │
│ 2024-10-01 16:13:20 │ fff │ 5424711 │
│ 2024-10-01 16:13:30 │ fff │ 5674669 │
│ 2024-10-01 16:13:40 │ fff │ 5947912 │
│ 2024-10-01 16:13:50 │ fff │ 6203361 │
│ 2024-10-01 16:14:00 │ fff │ 6501695 │
└─────────────────────┴──────┴─────────┘
Examples
Lets now have a look at how to use refreshable materialized views with some example datasets.
StackOverflow
The denormalizing data guide shows various techniques for denormalizing data using a StackOverflow dataset. We populate data into the following tables: votes, users, badges, posts, and postlinks.
In that guide, we showed how to denormalize the postlinks dataset onto the posts table with the following query:
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
We then showed how to do a one-time insert of this data into the posts_with_links table, but in a production system, we'd want to run this operation periodically.
Both the posts and postlinks table could potentially be updated. Therefore, rather than attempt to implement this join using incremental materialized views, it may be sufficient to simply schedule this query to run at a set interval, e.g., once every hour, storing the results in a post_with_links table.
This is where a refreshable materialized view helps, and we can create one with the following query:
CREATE MATERIALIZED VIEW posts_with_links_mv
REFRESH EVERY 1 HOUR TO posts_with_links AS
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
The view will execute immediately and every hour thereafter as configured to ensure updates to the source table are reflected. Importantly, when the query re-runs, the result set is atomically and transparently updated.
The syntax here is identical to an incremental materialized view, except we include a REFRESH clause:
IMDb
In the dbt and ClickHouse integration guide we populated an IMDb dataset with the following tables: actors, directors, genres, movie_directors, movies, and roles.
We can then write the following query can be used to compute a summary of each actor, ordered by the most movie appearances.
SELECT
id, any(actor_name) AS name, uniqExact(movie_id) AS movies,
round(avg(rank), 2) AS avg_rank, uniqExact(genre) AS genres,
uniqExact(director_name) AS directors, max(created_at) AS updated_at
FROM (
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id, imdb.movies.rank AS rank, genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY movies DESC
LIMIT 5;
┌─────id─┬─name─────────┬─num_movies─┬───────────avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 45332 │ Mel Blanc │ 909 │ 5.7884792542982515 │ 19 │ 148 │ 2024-11-11 12:01:35 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605094212635 │ 20 │ 301 │ 2024-11-11 12:01:35 │
│ 283127 │ Tom London │ 549 │ 2.8057034230202023 │ 18 │ 208 │ 2024-11-11 12:01:35 │
│ 356804 │ Bud Osborne │ 544 │ 1.9575342420755093 │ 16 │ 157 │ 2024-11-11 12:01:35 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-11-11 12:01:35 │
└────────┴──────────────┴────────────┴────────────────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.393 sec. Processed 5.45 million rows, 86.82 MB (13.87 million rows/s., 221.01 MB/s.)
Peak memory usage: 1.38 GiB.
It doesn't take too long to return a result, but let's say we want it to be even quicker and less computationally expensive. Suppose that this dataset is also subject to constant updates - movies are constantly released with new actors and directors also emerging.
It's time for a refreshable materialized view, so let's first create a target table for the results:
CREATE TABLE imdb.actor_summary
(
`id` UInt32,
`name` String,
`num_movies` UInt16,
`avg_rank` Float32,
`unique_genres` UInt16,
`uniq_directors` UInt16,
`updated_at` DateTime
)
ENGINE = MergeTree
ORDER BY num_movies
And now we can define the view:
CREATE MATERIALIZED VIEW imdb.actor_summary_mv
REFRESH EVERY 1 MINUTE TO imdb.actor_summary AS
SELECT
id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM
(
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC;
The view will execute immediately and every minute thereafter as configured to ensure updates to the source table are reflected. Our previous query to obtain a summary of actors becomes syntactically simpler and significantly faster!
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5
┌─────id─┬─name─────────┬─num_movies─┬──avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 45332 │ Mel Blanc │ 909 │ 5.7884793 │ 19 │ 148 │ 2024-11-11 12:01:35 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605 │ 20 │ 301 │ 2024-11-11 12:01:35 │
│ 283127 │ Tom London │ 549 │ 2.8057034 │ 18 │ 208 │ 2024-11-11 12:01:35 │
│ 356804 │ Bud Osborne │ 544 │ 1.9575342 │ 16 │ 157 │ 2024-11-11 12:01:35 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-11-11 12:01:35 │
└────────┴──────────────┴────────────┴───────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.007 sec.
Suppose we add a new actor, "Clicky McClickHouse" to our source data who happens to have appeared in a lot of films!
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
INSERT INTO imdb.roles SELECT
845466 AS actor_id,
id AS movie_id,
'Himself' AS role,
now() AS created_at
FROM imdb.movies
LIMIT 10000, 910;
Less than 60 seconds later, our target table is updated to reflect the prolific nature of Clicky’s acting:
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5;
┌─────id─┬─name────────────────┬─num_movies─┬──avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 845466 │ Clicky McClickHouse │ 910 │ 1.4687939 │ 21 │ 662 │ 2024-11-11 12:53:51 │
│ 45332 │ Mel Blanc │ 909 │ 5.7884793 │ 19 │ 148 │ 2024-11-11 12:01:35 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605 │ 20 │ 301 │ 2024-11-11 12:01:35 │
│ 283127 │ Tom London │ 549 │ 2.8057034 │ 18 │ 208 │ 2024-11-11 12:01:35 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-11-11 12:01:35 │
└────────┴─────────────────────┴────────────┴───────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.006 sec.