Question
How do I create a table that can query other clusters or instances?
Answer
Below is a simple example to test functionality.
In this example, ClickHouse Cloud is use but the example will work when using self-hosted clusters also. The targets will need to change to the urls/hosts/dns of a target node or load balancer.
In cluster A:
./clickhouse client --host clusterA.us-west-2.aws.clickhouse.cloud --secure --password 'Password123!'
Create the database:
create database db1;
Create the table:
CREATE TABLE db1.table1_remote1
(
`id` UInt32,
`timestamp_column` DateTime,
`string_column` String
)
ENGINE = MergeTree()
ORDER BY id;
Insert some sample rows:
insert into db1.table1_remote1
values
(1, '2023-09-29 00:01:00', 'a'),
(2, '2023-09-29 00:02:00', 'b'),
(3, '2023-09-29 00:03:00', 'c');
In cluster B:
./clickhouse client --host clusterB.us-east-2.aws.clickhouse.cloud --secure --password 'Password123!'
Create the database:
create database db1;
Create the table:
CREATE TABLE db1.table1_remote2
(
`id` UInt32,
`timestamp_column` DateTime,
`string_column` String
)
ENGINE = MergeTree()
ORDER BY id;
Insert sample rows:
insert into db1.table1_remote1
values
(4, '2023-09-29 00:04:00', 'x'),
(5, '2023-09-29 00:05:00', 'y'),
(6, '2023-09-29 00:06:00', 'z');
In Cluster C:
*this cluster will be used to gather the data from the other two clusters, however, can also be used as a source.
./clickhouse client --host clusterC.us-west-2.aws.clickhouse.cloud --secure --password 'Password123!'
Create the database:
create database db1;
Create the remote tables with remoteSecure() to connect to the other clusters.
Definition for remote cluster A table:
CREATE TABLE db1.table1_remote1_main
(
`id` UInt32,
`timestamp_column` DateTime,
`string_column` String
) AS remoteSecure('clusterA.us-west-2.aws.clickhouse.cloud:9440', 'db1.table1_remote1', 'default', 'Password123!');
Definition for remote cluster B table:
CREATE TABLE db1.table1_remote2_main
(
`id` UInt32,
`timestamp_column` DateTime,
`string_column` String
) AS remoteSecure('clusterB.us-east-2.aws.clickhouse.cloud:9440', 'db1.table1_remote2', 'default', 'Password123!')
Create the merge table to be used to gather results:
create table db1.table1_merge_remote
(
id UInt32,
timestamp_column DateTime,
string_column String
)
engine = Merge('db1', 'table.\_main');
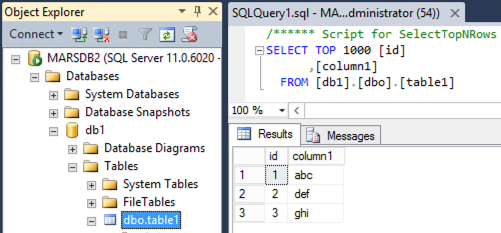
Test the results:
clickhouse-cloud :) select * from db1.table1_merge_remote;
SELECT *
FROM db1.table1_merge_remote
Query id: 46b6e741-bbd1-47ed-b40e-69ddb6e0c364
┌─id─┬────timestamp_column─┬─string_column─┐
│ 1 │ 2023-09-29 00:01:00 │ a │
│ 2 │ 2023-09-29 00:02:00 │ b │
│ 3 │ 2023-09-29 00:03:00 │ c │
└────┴─────────────────────┴───────────────┘
┌─id─┬────timestamp_column─┬─string_column─┐
│ 4 │ 2023-09-29 00:04:00 │ x │
│ 5 │ 2023-09-29 00:05:00 │ y │
│ 6 │ 2023-09-29 00:06:00 │ z │
└────┴─────────────────────┴───────────────┘
6 rows in set. Elapsed: 0.275 sec.
For more info:
https://clickhouse.com/docs/en/sql-reference/table-functions/remote
https://clickhouse.com/docs/en/engines/table-engines/special/merge